Visualizing SQL Schemas
I was recently tasked with examining databases related to some computer vision tools that my company had acquired. Basically, the framework was as follows… Clients/users would sign up for some service with the goal in mind of building a model to classify a set of microscopy images. These models could then be used by the client for downstream services. The users interacted with this tool through a web application, with which they could upload the training and validation datasets. They could also interact with models that they might have previously trained. The software used AWS EC2 instances to train and test their models, and a database to store all the relevant image files and metadata associated with the users and experiments.
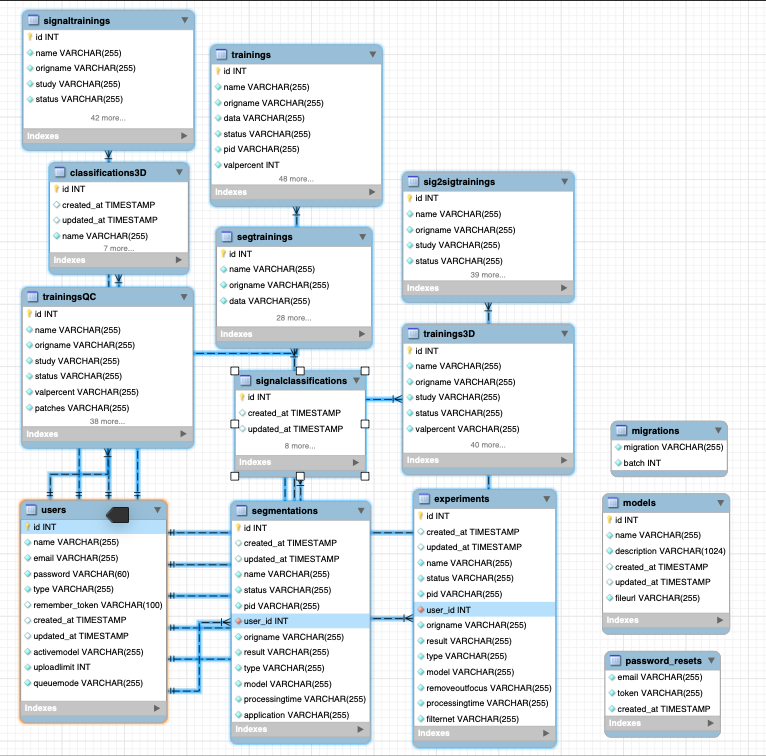
However, I was not provided with any relevant information about the database schema, rendering interpretation of the API and results difficult. Given that I had access to the MySQL database, I wanted to be able to visualize the interactions between all the relevant SQL tables.
Assuming that mysql and MySQL Workbench are installed, and that you know the database name and corresponding account password, you can run the following command to export the database to an SQL file. The -u, -p, and --no-data options correspond to the user ID, password, and desire (or lack thereof) to export the data entries as well.
mysqldump -u root -p --no-data ${DB_NAME} > ${OUTPUT_NAME}.sql
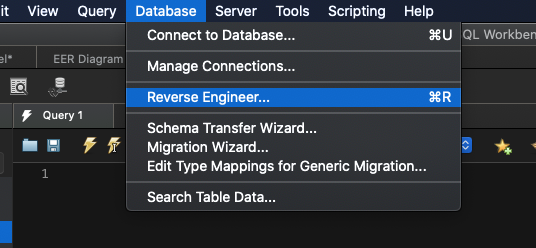
You can then reverse engineer the database schema by clicking Database -> Reverse Engineer and subsequent the steps:
We can then actually visualize the database schema and table structures in MySQL Workbench. Below, we see that all SQL tables are joined to the table called users via their corresponding user_id field. At a minimum, we’ll be able to sort experiments by user_id – however, I’m hoping there is also a join for model_name or something along those lines, so that we can more easily interrogate the specific parameterizations of each model.